
Getting Started with Docker Model Runner
This is the first out-of-sequence tutorial that focuses on Docker Model Runner

This edition focuses on understanding what Docker Model Runner is and how to set it up. By the end of this tutorial, you will be able to:
Enable Docker Model Runner
Pull LLMs from Docker Hub
Run LLMs locally using both the CLI and Docker Desktop UI
Tutorial level: Beginner
In the coming editions, we will focus on working with Docker Model Runner with Python using the OpenAI Python API SDK and review how to pull models from Hugging Face.
Let’s get started!

What Docker Model Runner Is
The Docker Model Runner (DMR) - a new Docker Desktop feature that enables the run of Large Language Models natively with Docker Desktop. This feature follows the common Docker workflow:
Pull models from registries (e.g., Docker Hub)
Run models locally with GPU acceleration
Integrate models into the development workflows
Of course, the LLMs' performance is derived from the model size and resources available locally.
This feature is currently under Beta, and required Docker Engine (Linux) or Docker Desktop 4.40 and above for MacOS, and Docker Desktop 4.41 for Windows Docker Engine. For hardware requirements, please check the Docker Model Runner documentation
The goal of this feature is to enable developers to test and run AI models locally seamlessly using familiar Docker CLI commands and tools.
Key Features:
Run LLMs locally, enabling users to run the models with full privacy control
Supports a curated catalog of open-source LLM on Ducker Hub and Hugging Face models
Native GPU acceleration, fully utilize and optimize local resources
Fully integrate with the Docker workflow and tools
Following the previous point, you can package and share the models using the Docker registry framework, such as Docker Hub
Manage local models and display logs
The Docker Model Runner runs AI models using a host-installed inference server. It uses the llama.cpp framework, which enables running LLM inference using C/C++ and "talking" directly with the hardware GPU acceleration on Apple Silicon on Mac OS and NVIDIA GPUs on Windows OS. Therefore, it enables better optimization of local resources and faster deployment, as opposed to running LLM inside a container.
Models
Working with LLMs with the Model Runner is fairly similar to working with containers. The core supported LLMs are available on Docker Hub, including models such as Meta’s Llama 3, Microsoft Phi 4, Google Gemma 3, and Mistral Instruct.
In addition to the core supported models on Docker Hub, it supports direct download of models from Hugging Face via the CLI. We will review this functionality in a future issue.
Getting Started with Docker Model Runner
To run LLMs locally with the DMR, you will need the following:
Docker Engine (Linux), or Docker Desktop version 4.40.0 (MacOS) and version 4.41.0 (Windows) and above
Docker Hub account (required to access LLMs)
Optional - Hugging Face account
There are two methods to interact with DMR:
Docker Desktop
CLI
Both methods are straightforward to use, and they include the following steps:
Enabling the feature (required as long as it is under Beta)
Pulling a model
Launching the model
Let’s review both methods.
Running LLMs with DMR Using Docker Desktop
Let’s start by enabling the feature. On the Docker Desktop settings menu, go to the Beta features option (marked in purple) and select the Enable Docker Model Runner option (marked in yellow):
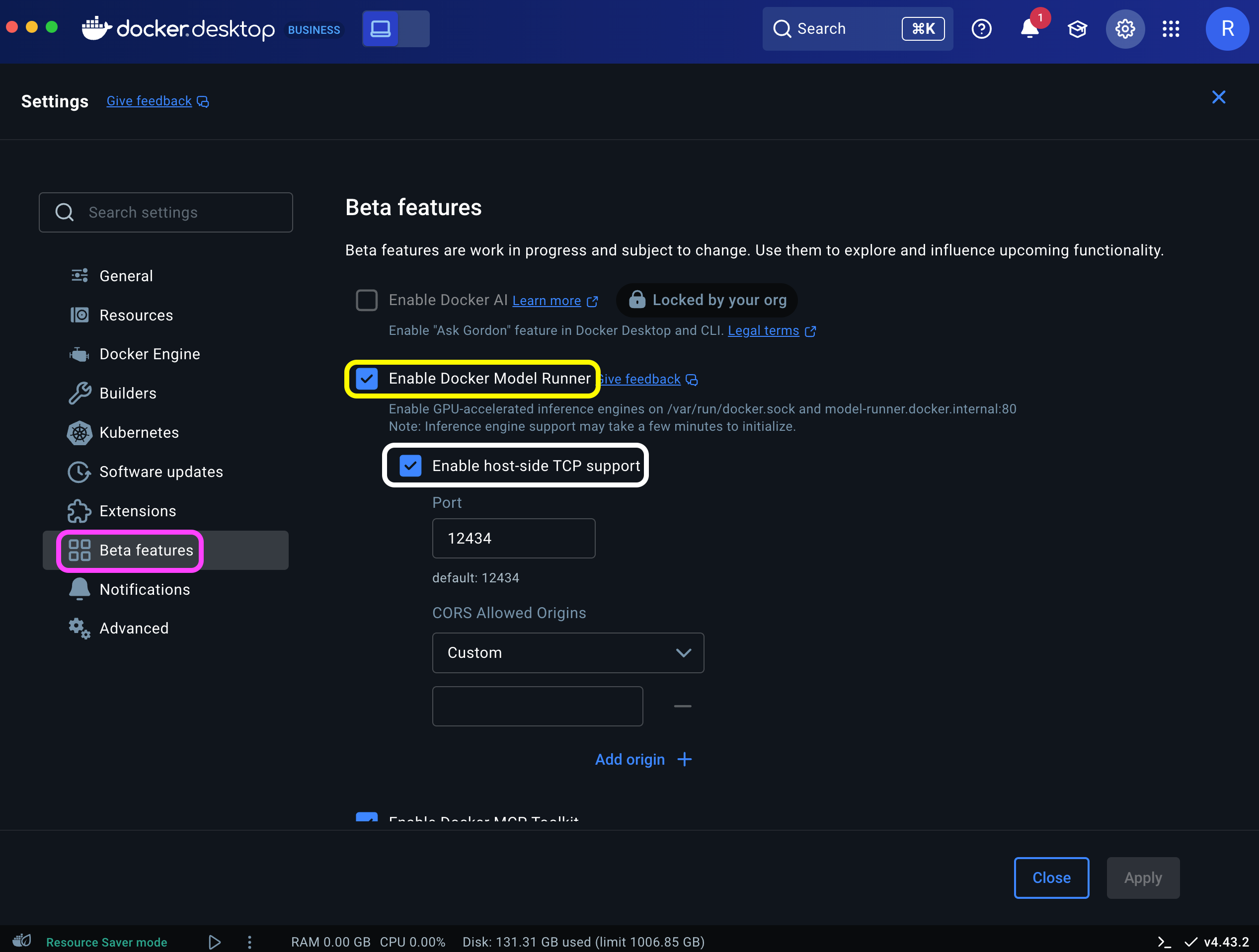
The host-side TCP support option (marked in white) enables you to expose LLMs using TCP (Transmission Control Protocol) to a port. This is something we will review in the next tutorial.
Next, let’s use Docker Desktop Dashboard to pull LLM from Docker Hub using the Models menu (marked in purple). If this is the first time you use this feature or you don’t have any model locally, you should have the following view:
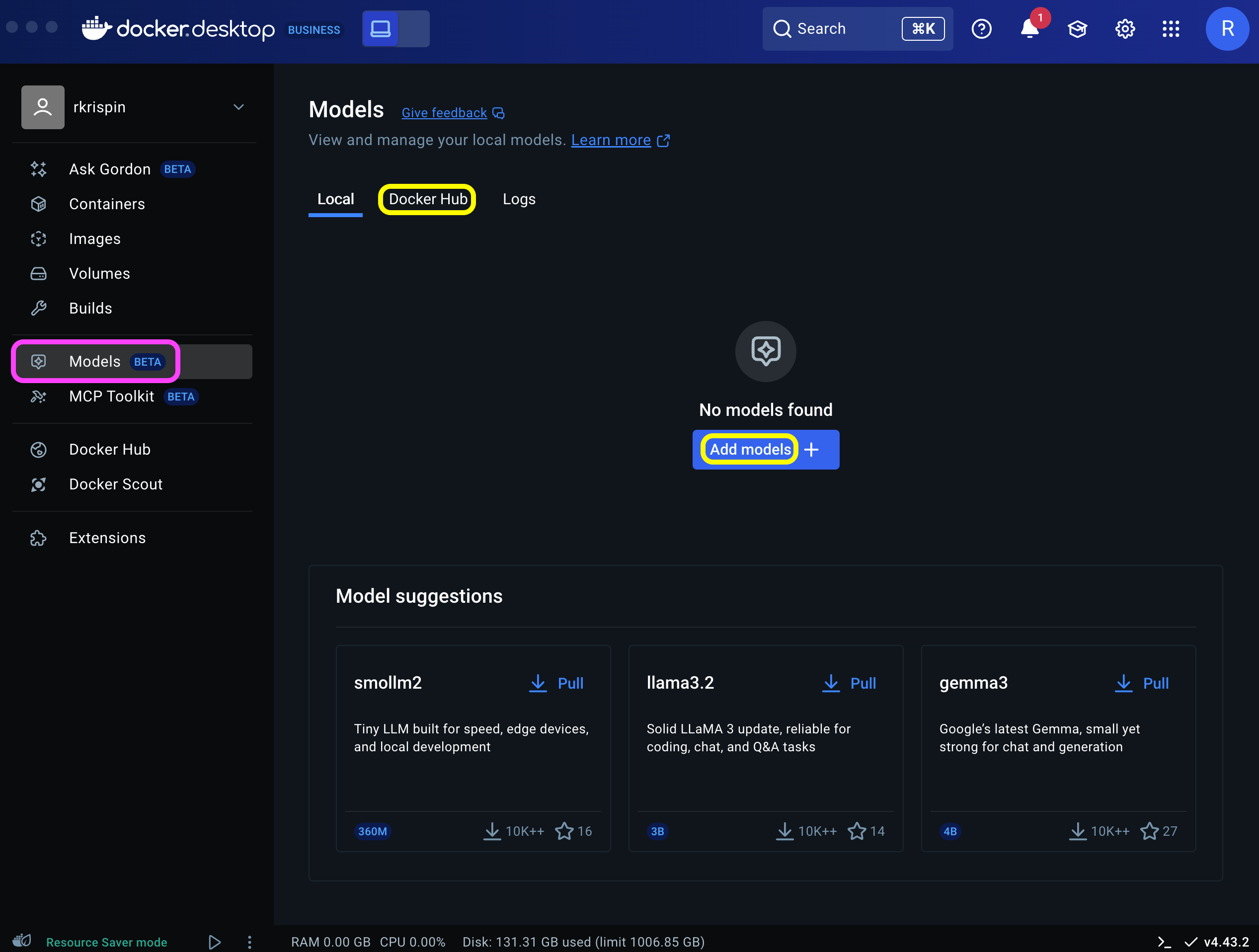
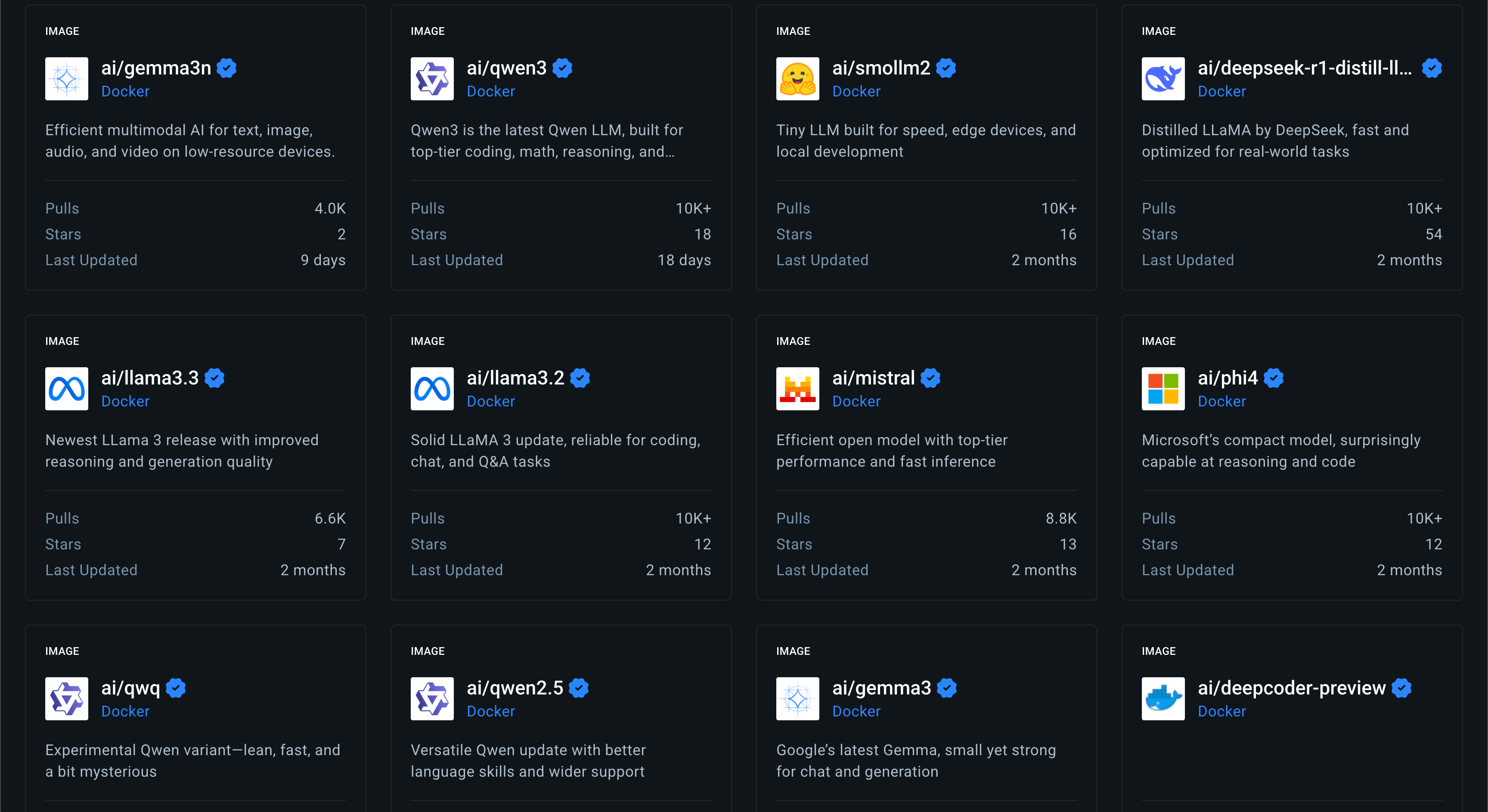
To get a list of available models on Docker Hub, click either the Docker Hub tab or the Add models button (both marked in yellow). This will lead you to the following screen, providing the available LLMs to pull:
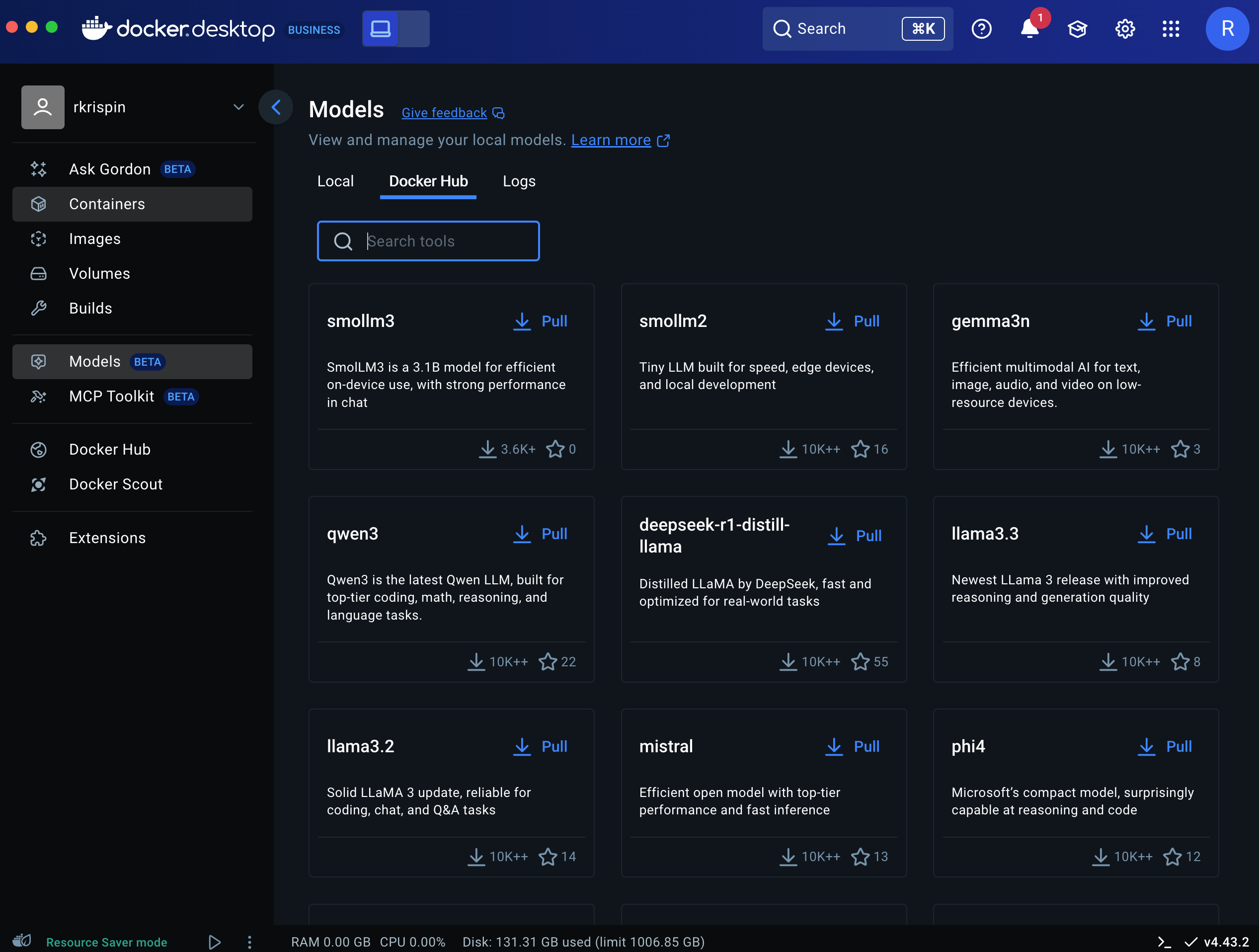
If you click the model box, you can get the model description, which includes versions, number of parameters, context window, size, format, etc. For example, let’s review the properties of the Llama 3.2 model and available versions:
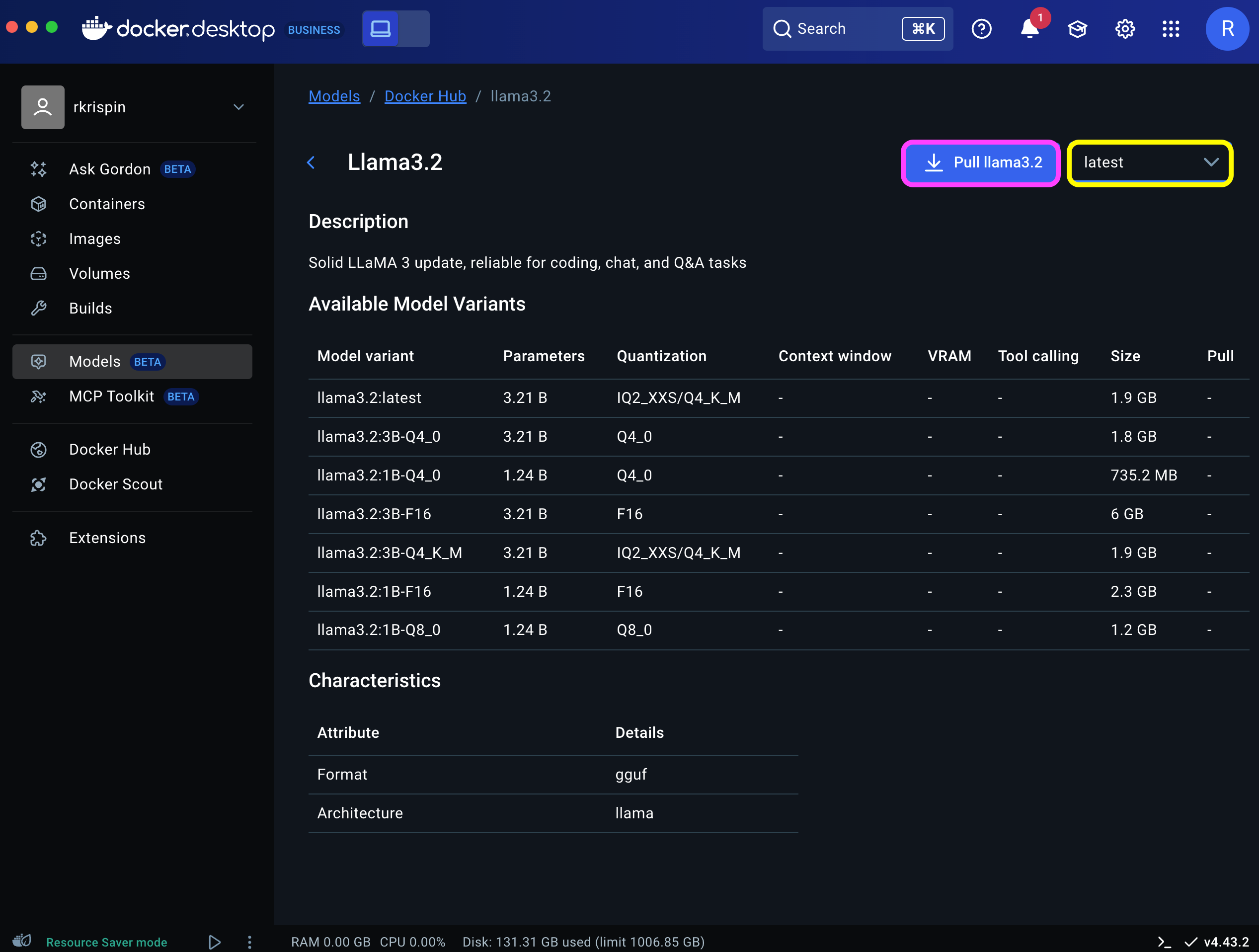
We will download the model’s latest version using the Pull llama3.2 button (marked in purple). You can select a different version of the model using the drop-down selector to the right (marked in yellow).
The model should now be available under the Local tab:
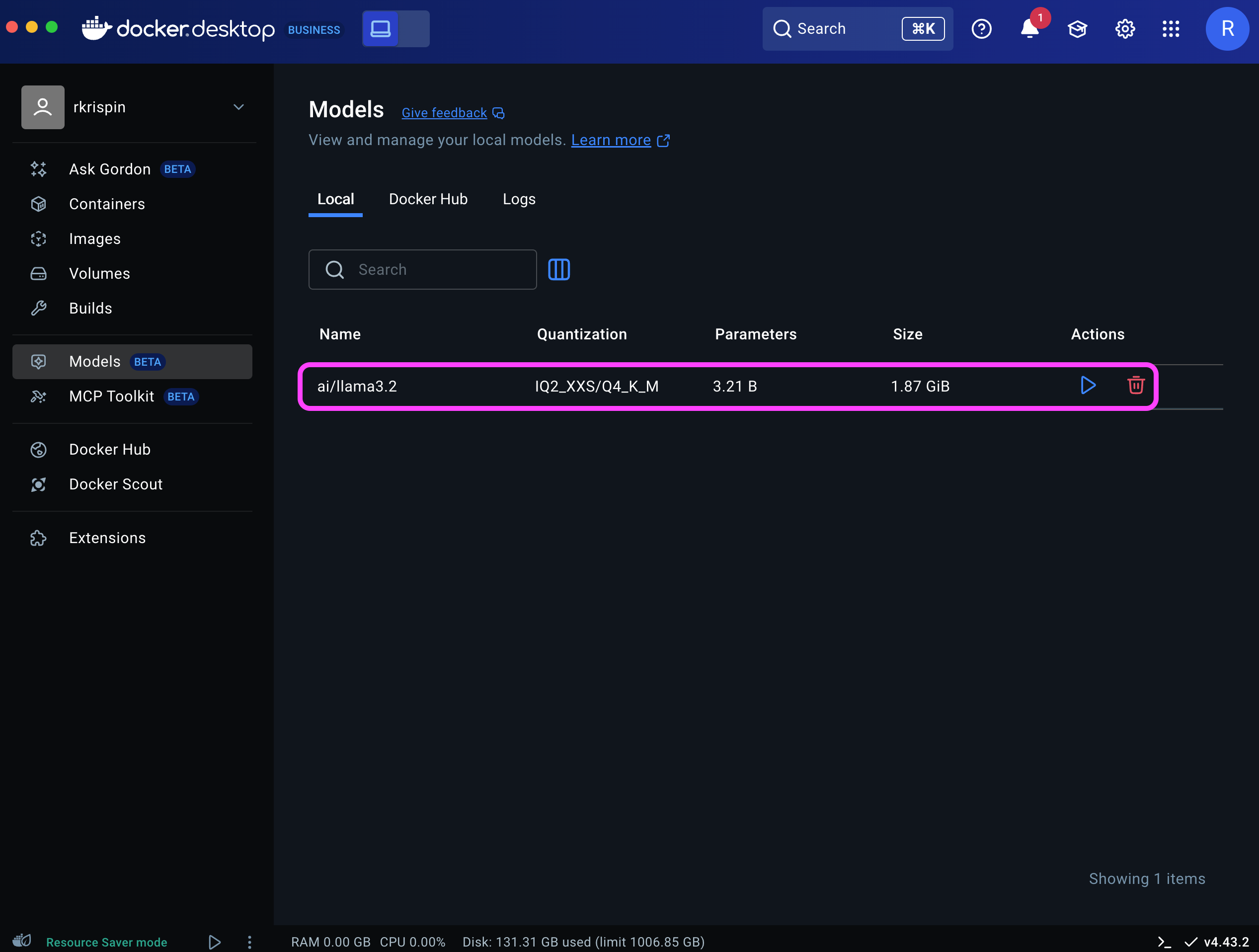
Although the model is not stored as a Docker image, it operates like one. This means that, similar to a Docker image, you need to launch (or run) the model first in order to interact with it.
You can delete a model using the trash icon under the Actions column
Let’s click the Play button under the Actions column to launch the model:
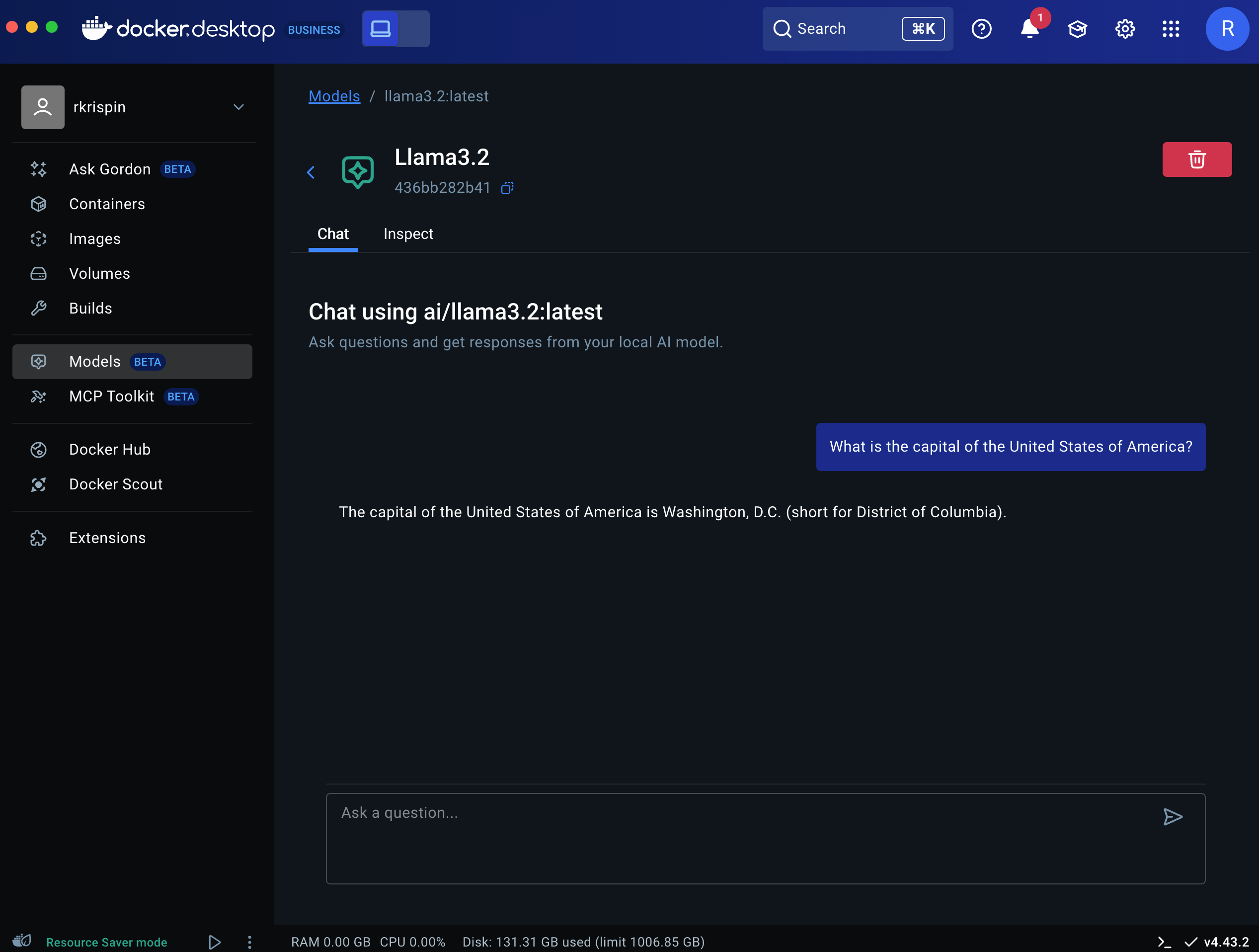
The model is now active in a chat mode, and you can send your questions via the chat box.
Last but not least, you can use the Logs tab to review the model logs:
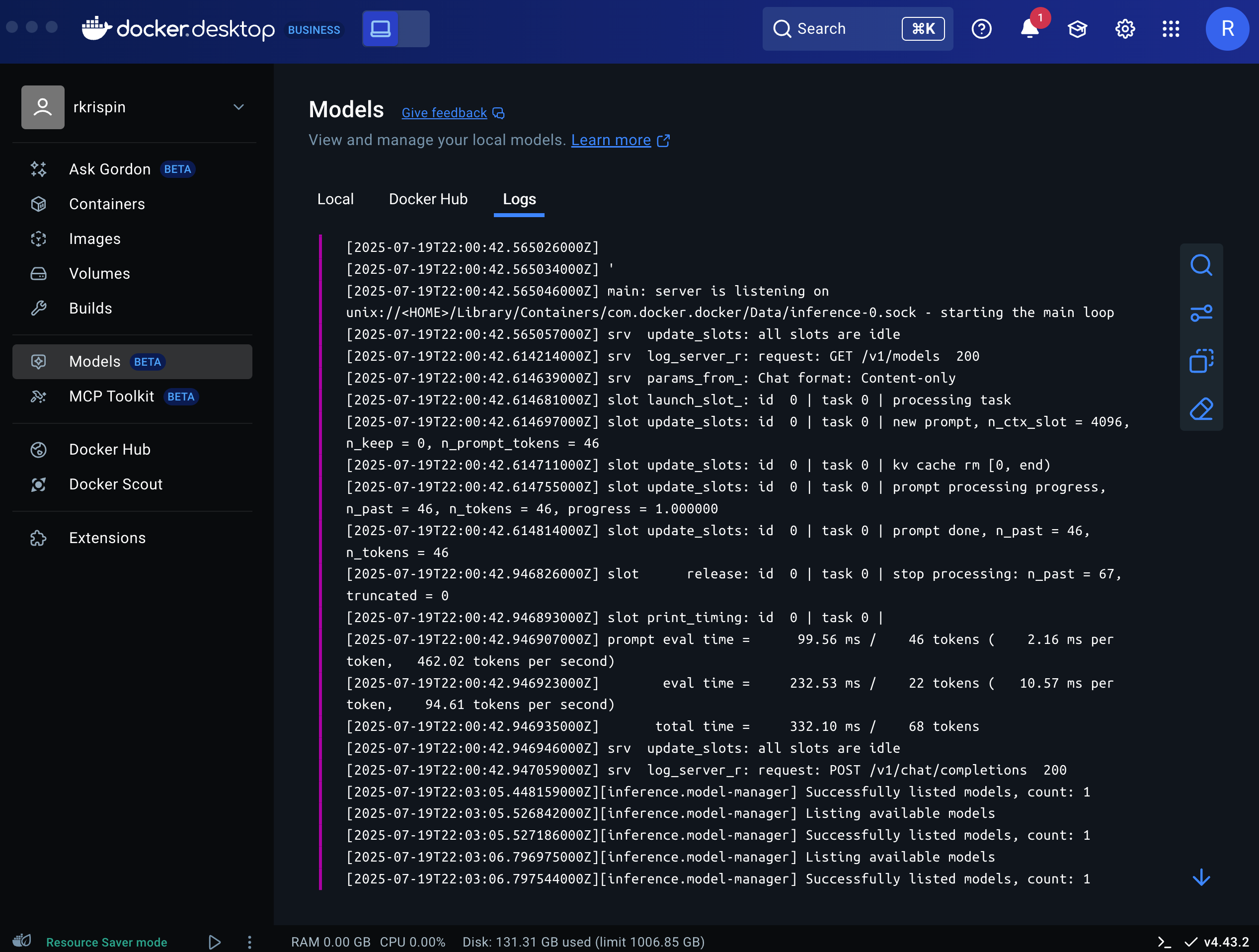
Running LLMs with DMR via the CLI
Let’s now repeat the same steps, this time using the CLI. Let’s start by enabling the DMR feature:
docker desktop enable model-runnerIf you want to expose the model using TCP, you can add the tcp argument to set the port.
The interaction with the DMR on the CLI is done with the docker model command. You can see its arguments using the —help argument. To validate that the feature is available and enabled, you use the docker model status command:
docker model statusYou should expect the following output:
Docker Model Runner is runningNext, let’s review what models are available locally using the list command:
docker model listThis returns the following output:
MODEL NAME PARAMETERS QUANTIZATION ARCHITECTURE MODEL ID CREATED SIZE
ai/llama3.2:latest 3.21 B IQ2_XXS/Q4_K_M llama 436bb282b419 3 months ago 1.87 GiBYou can notice that the model we pulled earlier using the Docker Desktop UI is listed in the output.
Like regular images, we can use the pull command to pull models from Docker Hub. For example, let’s pull the latest version of the gemma3n model:
docker model pull ai/gemma3n:latestWe can confirm that the model is available using the list command again. This will return the following output:
MODEL NAME PARAMETERS QUANTIZATION ARCHITECTURE MODEL ID CREATED SIZE
ai/llama3.2:latest 3.21 B IQ2_XXS/Q4_K_M llama 436bb282b419 3 months ago 1.87 GiB
ai/gemma3n:latest 6.87 B IQ2_XXS/Q4_K_M gemma3n 800c2ac86449 3 weeks ago 3.94 GiBThe inspect command provides the model metadata:
docker model inspect ai/gemma3nThis returns the metadata in a JSON format:
{
"id": "sha256:800c2ac86449991e1f69edb098e27ff51a73a7726fa39ddd9e082f7ebe64cd07",
"tags": [
"ai/gemma3n:latest"
],
"created": 1751012329,
"config": {
"format": "gguf",
"quantization": "IQ2_XXS/Q4_K_M",
"parameters": "6.87 B",
"architecture": "gemma3n",
"size": "3.94 GiB",
.
.
.
"tokenizer.ggml.add_bos_token": "true",
"tokenizer.ggml.add_eos_token": "false",
"tokenizer.ggml.add_sep_token": "false",
"tokenizer.ggml.add_space_prefix": "false",
"tokenizer.ggml.bos_token_id": "2",
"tokenizer.ggml.eos_token_id": "1",
"tokenizer.ggml.model": "llama",
"tokenizer.ggml.padding_token_id": "0",
"tokenizer.ggml.pre": "default",
"tokenizer.ggml.unknown_token_id": "3"
}
}
}Let’s now launch the gemma3n model using the run command. This will launch the LLM in a chat mode:
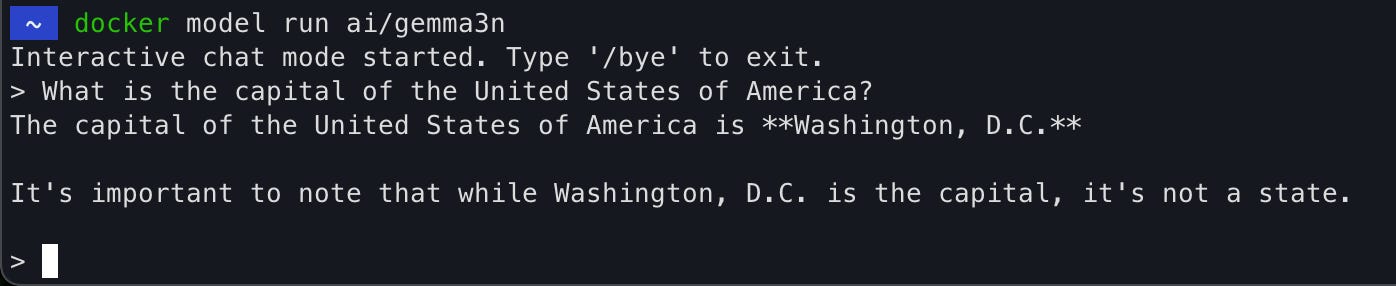
Last but not least, you can access the DMR logs using the logs command:
docker model logsSummary
The Docker Model Runner is a new feature of Docker Desktop that enables running LLMs locally using a host-installed inference server. It efficiently utilizes local resources and hardware and seamlessly integrates with the containerized workflow. This enables developers to integrate LLM seamlessly into the development life cycle with full privacy control.
In this tutorial, we introduced how to set it up, pull, and launch a model using both Docker Desktop and CLI. The DMR is fully compatible with the OpenAI API SDKs, enabling seamless use of the DMR with minimal changes in your code. In the next tutorial, we will focus on leveraging the OpenAI API Python SDK to interact with LLMs with Python.
Resources
Docker Desktop documentation - https://docs.docker.com/desktop/
Docker Model Runner Documentation - https://docs.docker.com/ai/model-runner/
Available LLMs on Docker Hub - https://hub.docker.com/u/ai
I will try this week !