
Running LLMs Locally with Docker Model Runner and Python
This is the second tutorial on the Docker Model Runner sequence

In the previous issue, we introduced Docker Model Runner (DMR) and explored how to run and interact with LLMs locally using both the terminal and the Docker Desktop UI. In this tutorial, we'll take the next step by using the OpenAI Python SDK to work with DMR directly from Python.
By the end, you'll be able to run and interact with LLMs locally through Python code.
Tutorial level: Beginner
In the next issue, we'll cover how to pull models from Hugging Face into DMR.
Let’s get started!

One of the great features of Docker Model Runner is its compatibility with the OpenAI API SDKs. This makes it easy to adapt existing code that uses the OpenAI API to work with DMR and interact with locally running LLMs. In this tutorial, we'll focus on the Python SDK, though the same approach applies to other OpenAI SDKs like JavaScript, Java, Go, .NET, and more.
The prerequisite for running DMR is Docker Engine (Linux) or Docker Desktop 4.40 and above for MacOS, and Docker Desktop 4.41 for Windows Docker Engine. For hardware requirements, please check the Docker Model Runner documentation
DMR runs as a standalone server so that you can connect to it from both containerized environments and regular local Python environments.
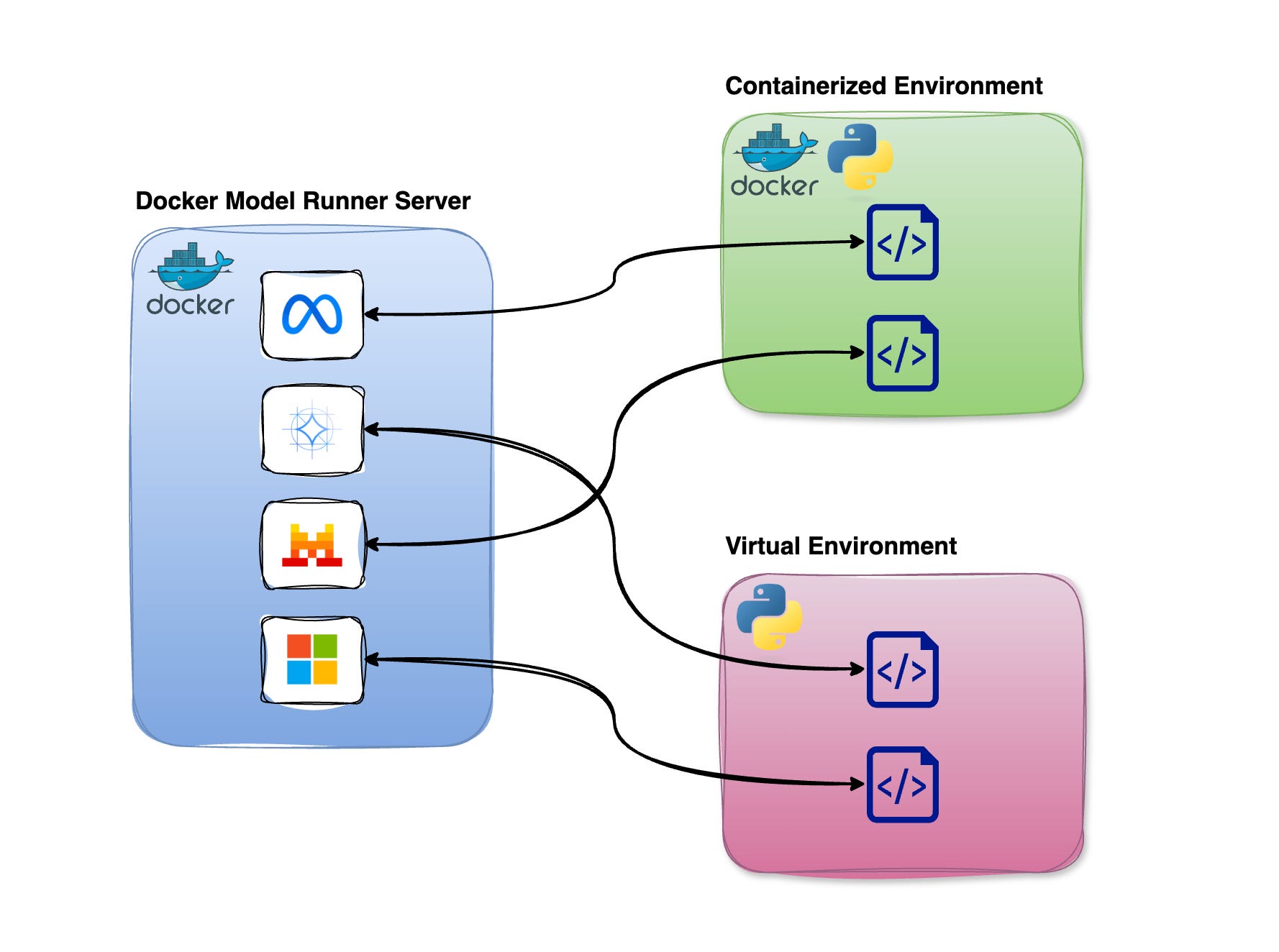
This flexibility gives you the choice to either containerize your Python setup or stick with a traditional virtual environment—whatever works best for your workflow.
OpenAI API Python SDK Workflow
Now, let’s walk through how to configure the OpenAI Python SDK to interact with models running locally via DMR.
A typical OpenAI workflow in Python involves the following steps:
Import the
openailibrarySet up a client by specifying API details (e.g., base URL, API key)
Define a prompt and send it as a request to the OpenAI API
Parse and use the API response
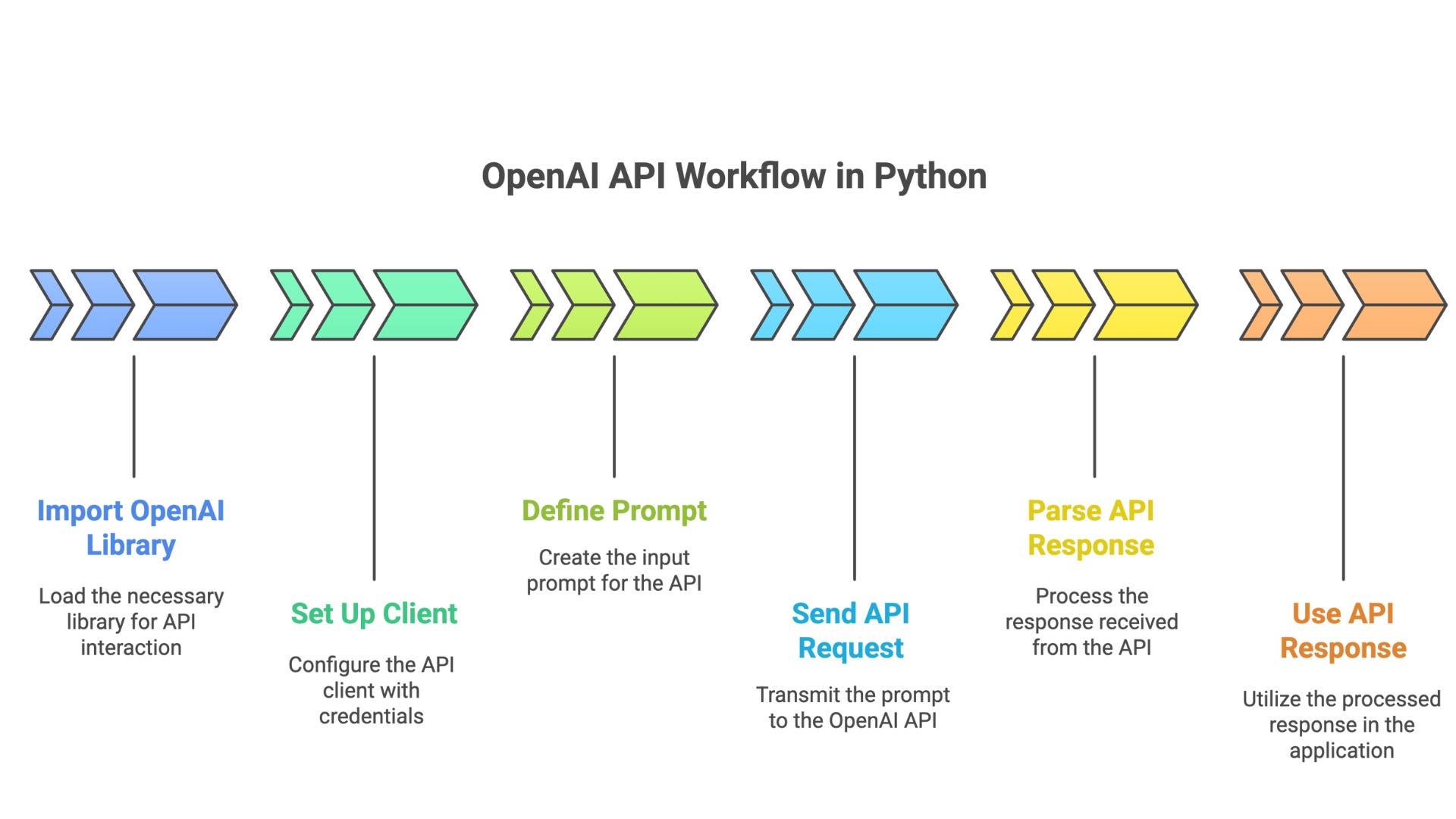
The DMR follows this same workflow, with just one key difference: you'll use the DMR server’s URL instead of the official OpenAI endpoint when configuring the client. In addition, we will define the specific model we want to leverage from the available local models.
In the next example, we'll show you how to "chat" with an LLM using the OpenAI Python SDK and a locally running DMR instance.
Docker Model Runner Settings
Before we dive into the Python code, let’s first make sure that DMR is up and running. You can do this from the command line using the status command:
docker model statusIf everything is working correctly, you should see output similar to this:
Docker Model Runner is running
Status:
llama.cpp: running llama.cpp latest-metal (sha256:3f229388659b4b647d9dec47e1af843f874ca8bf8e43a336828362d9afad394c) version: 79e0b68Next, list the available local models using:
docker model listCurrently, the following two models are available locally:
MODEL NAME PARAMETERS QUANTIZATION ARCHITECTURE MODEL ID CREATED SIZE
ai/llama3.2:latest 3.21 B IQ2_XXS/Q4_K_M llama 436bb282b419 4 months ago 1.87 GiB
ai/gemma3n:latest 6.87 B IQ2_XXS/Q4_K_M gemma3n 800c2ac86449 4 weeks ago 3.94 GiBBefore connecting to the model from Python, you'll need to enable Transmission Control Protocol (TCP) access and set the port number. This step defines the local host address and allows the OpenAI SDK to communicate with the DMR server.
You can enable TCP and configure the port via the Docker Desktop Settings dashboard (highlighted in white):
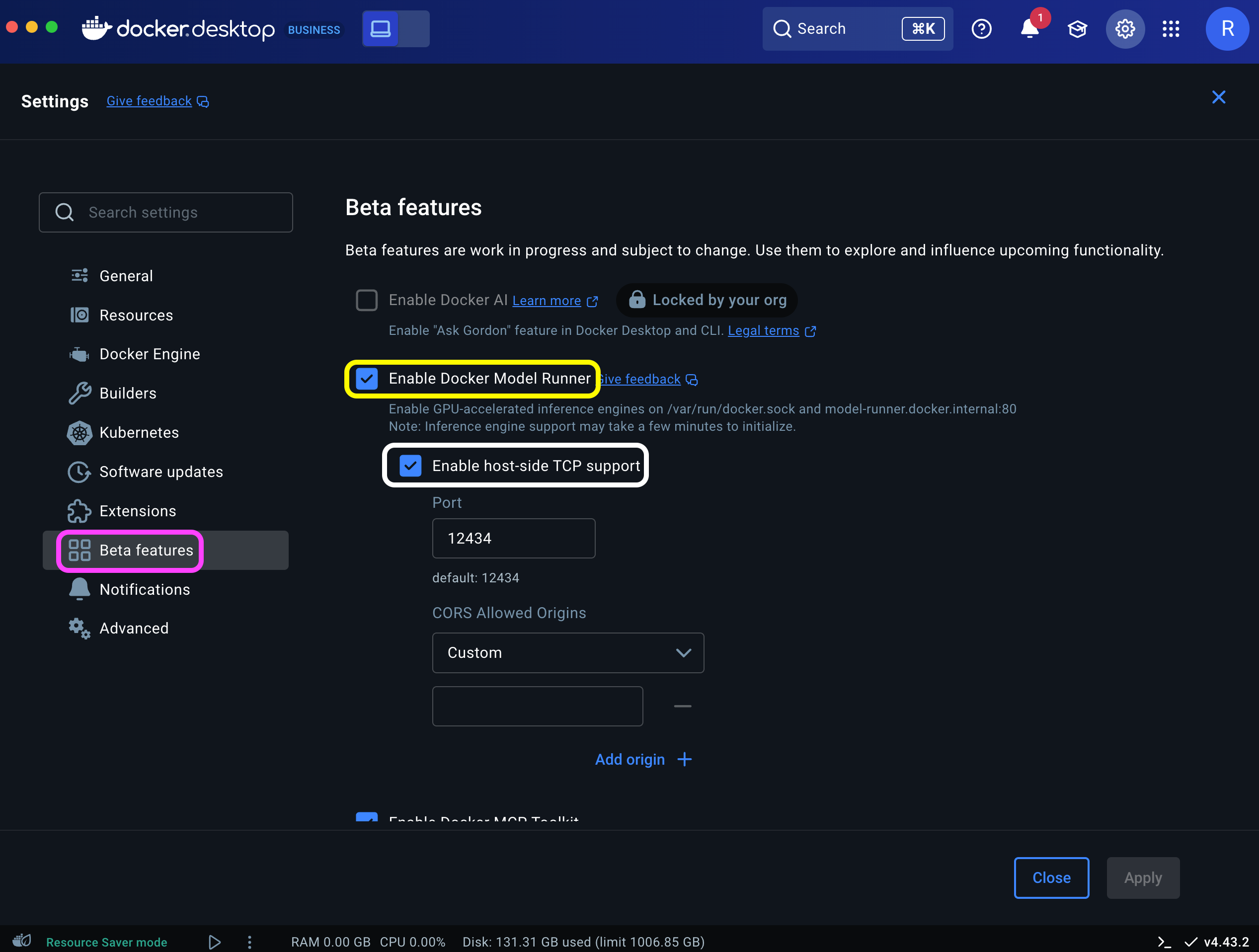
Or simple run the following command on the CLI:
docker desktop enable model-runner --tcp=12434This will expose the server on port 12434.
Working with the Python SDK
Now let’s switch over to Python and send a simple prompt to the Llama model. We’ll start by importing the openai library:
import openaiNext, we’ll define the client using the OpenAI function. To connect to the DMR server, we need to set the base_url parameter. The value of this URL depends on whether you're running the code inside a container or from your local environment.
If you're running the code inside a container, use the following:
base_url= "http://model-runner.docker.internal/engines/v1"If you're running it locally (outside of a container), use:
base_url = "http://localhost:12434/engines/v1"Note that the localhost should point to the TCP port, in this case 12434.
Now, initialize the OpenAI client:
client = openai.OpenAI(
base_url = base_url,
api_key = "docker"
)With the client set up, the rest of the workflow is exactly the same as using the OpenAI API. For example, here’s how you can use chat.completions.create to ask the following question:
What is the capital of the United States of America?
completion = client.chat.completions.create(
model="ai/llama3.2:latest",
messages=[
{"role": "system", "content": "You are a helpful AI assistant."},
{"role": "user", "content": "What is the capital of the United States of America?"}
],
)We use the model argument to reference the LLM, in this case llama 3.2, and set the prompt using the message argument. Last but not least, we will parse and print the return answer from the LLM:
print(completion.choices[0].message.content)This returns the following output:
The capital of the United States of America is Washington, D.C.Summary
In this tutorial, we explored how to interact with LLMs running locally via Docker Model Runner using Python. Thanks to DMR's compatibility with the OpenAI API SDK, adapting your Python code to run models locally is simple and seamless.
In the next issue, we’ll walk through how to download and run LLMs from Hugging Face using DMR.
Resources
Getting Started with Docker Model Runner - link
Docker Desktop documentation - https://docs.docker.com/desktop/
Docker Model Runner Documentation - https://docs.docker.com/ai/model-runner/
Available LLMs on Docker Hub - https://hub.docker.com/u/ai
OpenAI API SDK - https://platform.openai.com/docs/libraries