
Docker Model Runner - Pull LLMs from Hugging Face
This is the third tutorial in the Docker Model Runner sequence

In previous issues, we demonstrated how to pull LLMs from Docker Hub and run them locally using Docker Modder Runner (DMR). This issue focuses on running LLMs from Hugging Face with DMR.
By the end of this tutorial, you will be able to: identify models that support DMR on Hugging Face, determine the model name and tag, and pull and run the model locally with DMR.
Tutorial level: Beginner
So far in the sequence:
✅ Getting Started with Docker Model Runner
✅ Running LLMs Locally with Docker Model Runner and Python
📌 Docker Model Runner - Pull LLMs from Hugging Face
Let’s get started!

As we mentioned in previous issues, Docker Model Runner (DMR) makes it easy to pull, run, and serve LLMs and other AI models directly from Docker Hub. It also works with any Open Container Initiative (OCI)–compatible registry and supports the GGUF file format for packaging models as OCI Artifacts. In practice, this means you can pull models not only from Docker Hub but also from the largest AI model registry — Hugging Face.

LLMs are stored and handled much like container images:
They live in a container registry
You pull them with a dedicated command
They follow a similar naming convention:
REGISTRY_NAME/LLM_NAME:TAG

For example, the Llama 3.2 model on Docker Hub would be labeled as:
ai/llama3.2:latestHere, ai is the registry namespace (Docker Hub in this case), llama3.2 is the model name, and latest is the tag.
By following this familiar container workflow, DMR lets you treat models just like images, making it easier to manage, share, and deploy them locally.
In the following section, we will review how to find models with support for DMR and pull them to run locally.
Pulling Models from Hugging Face
Hugging Face is often called the “GitHub of AI models.” It hosts over 1.7 million models for a wide range of use cases, including text generation, image-to-text, text-to-image, text-to-speech, and more. The site includes powerful search and filtering tools that let you find models by functionality, number of parameters, supported platforms, and other criteria, making it easy to locate models that work with DMR.
Models with DMR Support
To find models with DMR support:
Go to the Hugging Face website.
Select the Models tab (marked in purple).
In the App section on the left-hand menu (marked in yellow), click Expand (marked in light blue).
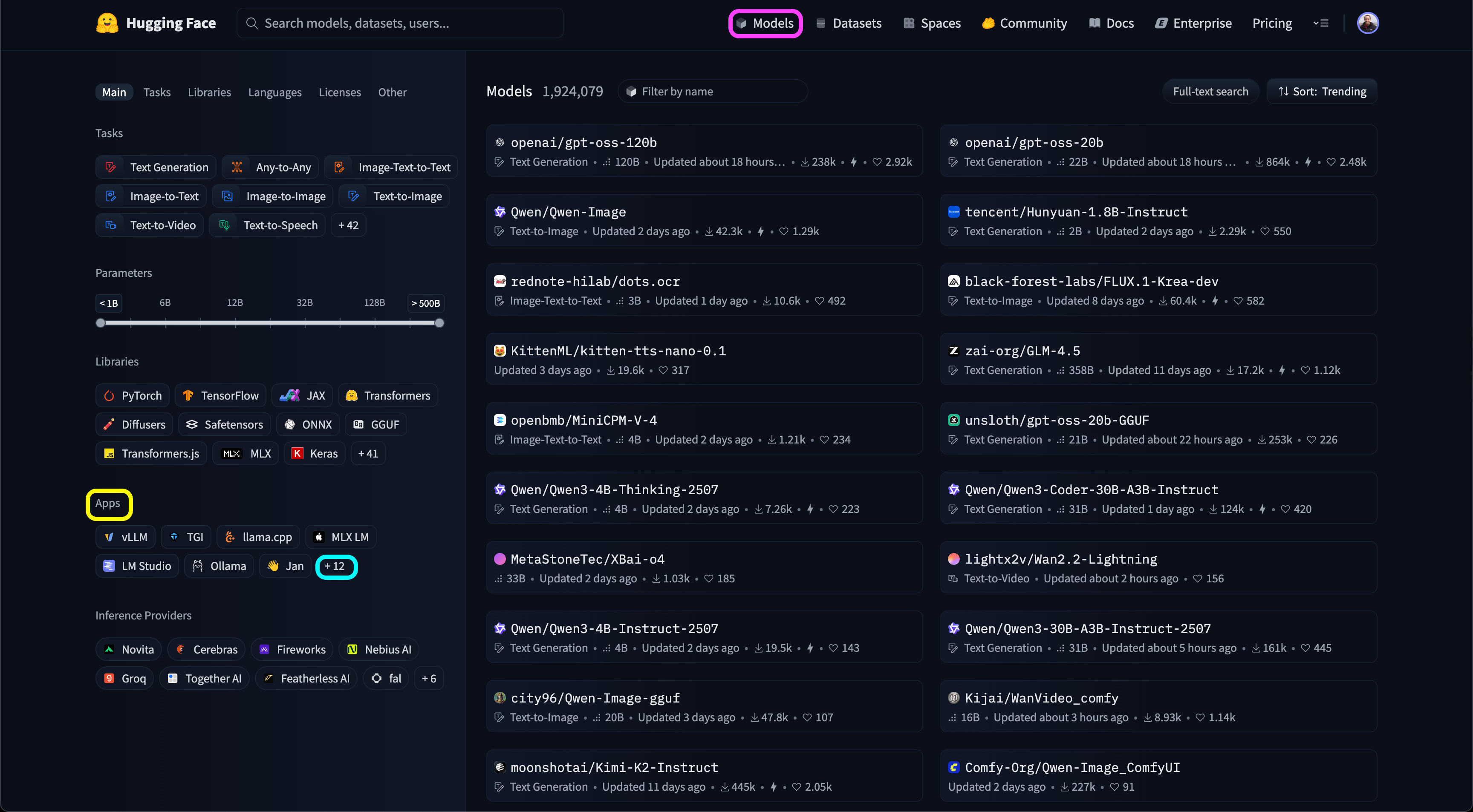
From the list of supported apps, choose Docker Model Runner (marked in purple):
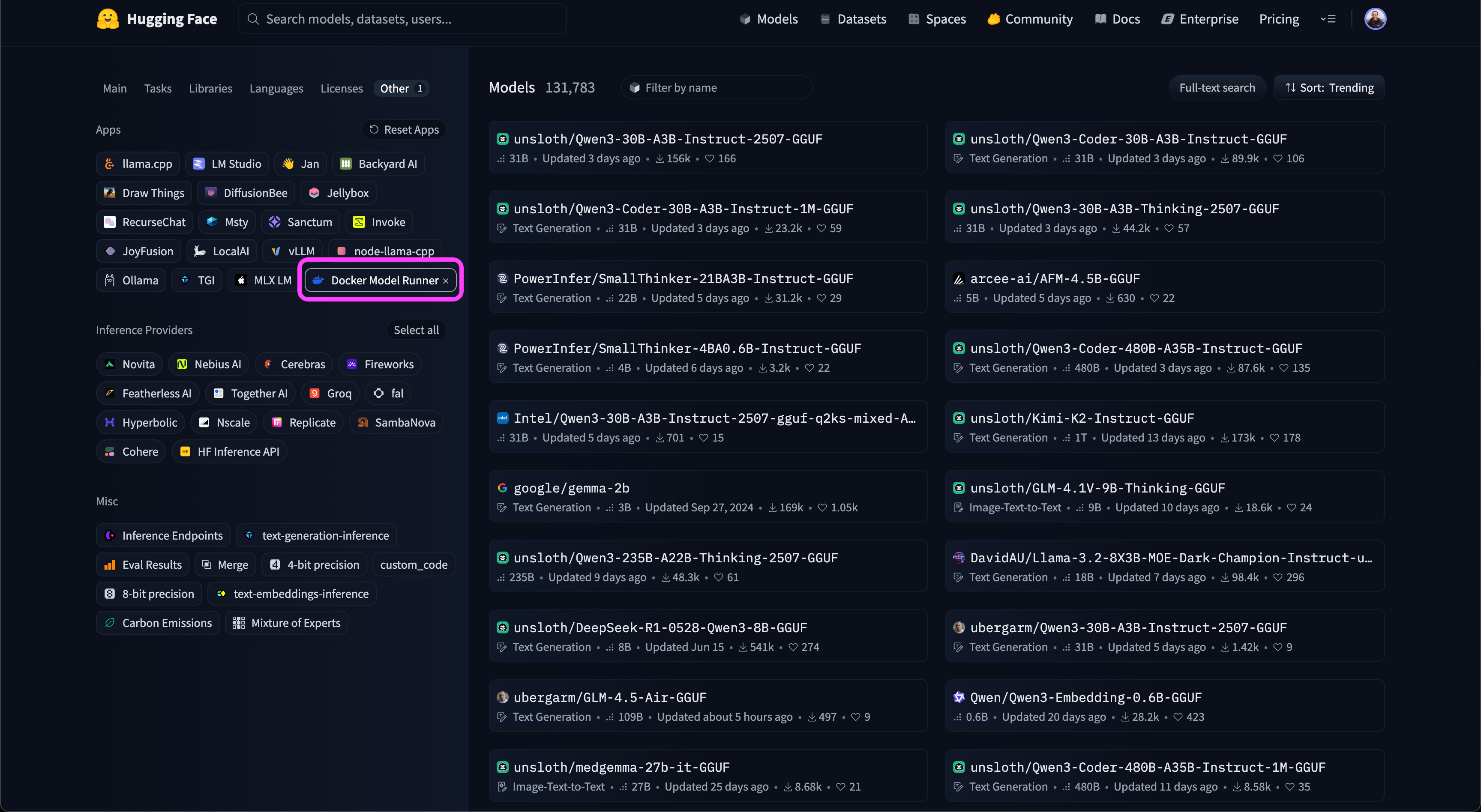
The models displayed on the right now all support DMR.
Other useful filters include:
Tasks — choose the type of model (e.g., Text Generation)
Parameters — set a range for the number of model parameters (marked in green)
For this example, we’ll select the Text Generation task (marked in purple) and limit the parameters to 1–6 billion.
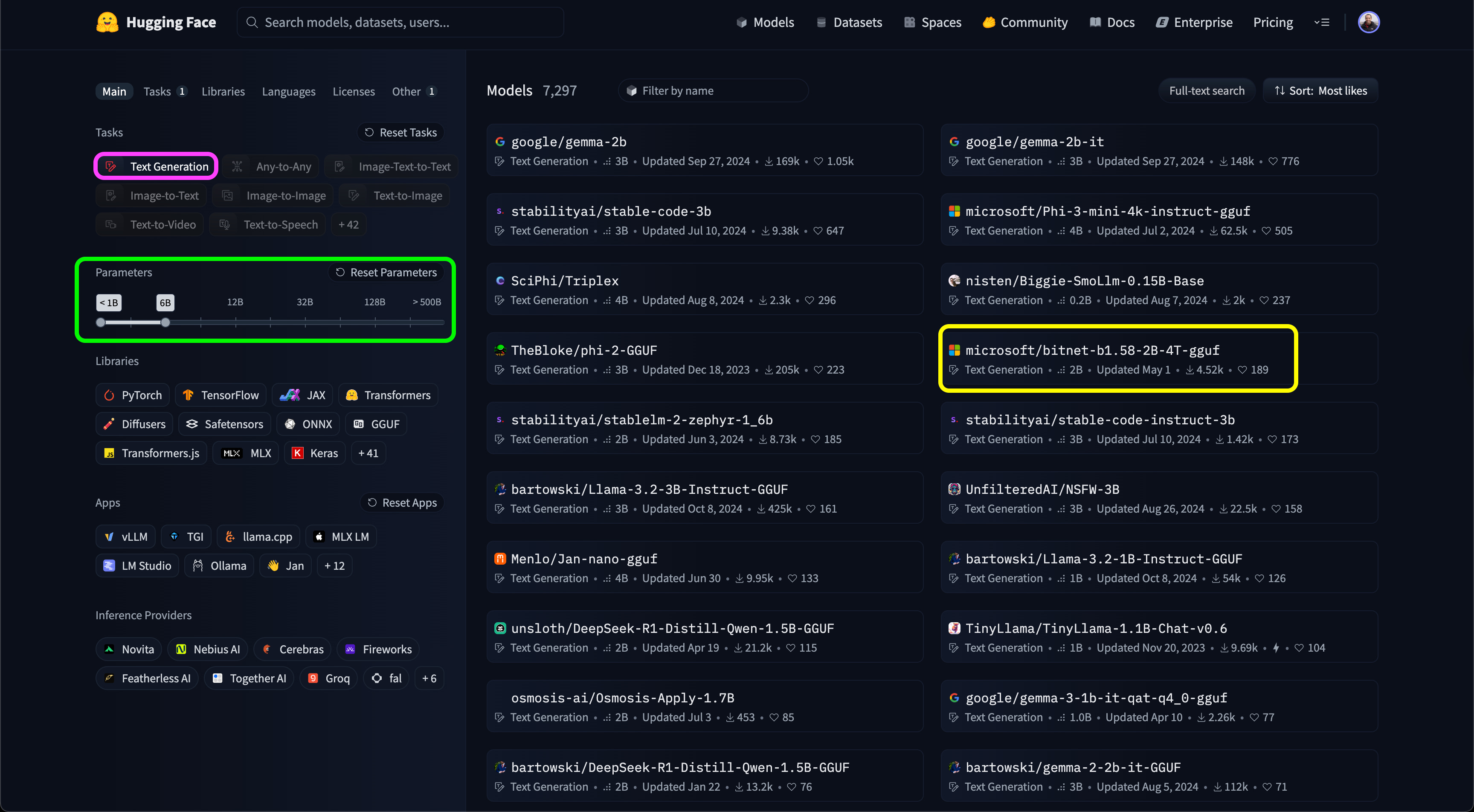
Finally, for our demo, we’ll pick Microsoft’s Phi-3-mini-4k-instruc model (marked in yellow) and open its model page:
The Use this model drop-down (marked in purple) button provides the list of supported platforms, and we will select the Docker Model Runner option (marked in yellow).
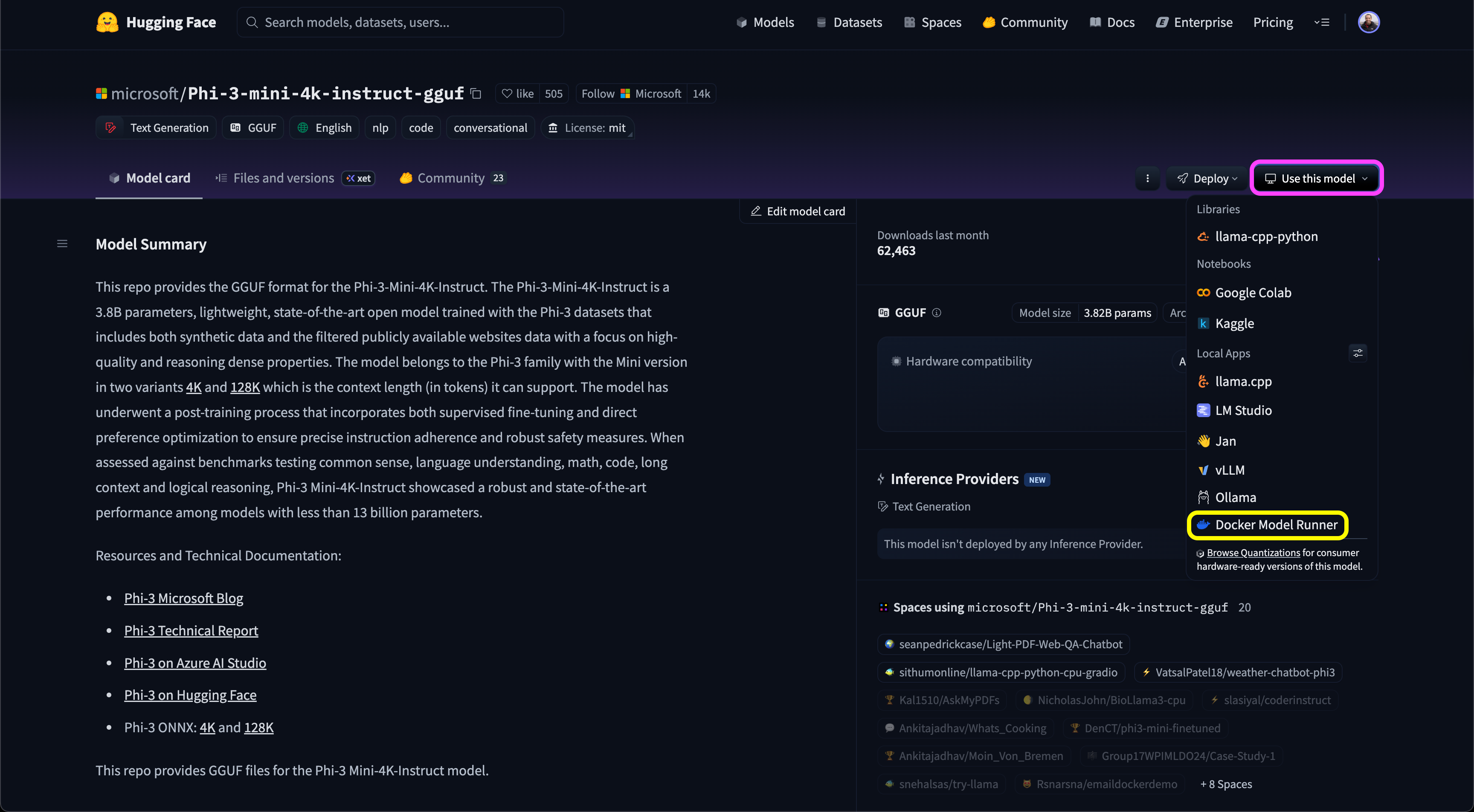
This will prompt the DMR command to run the model locally:
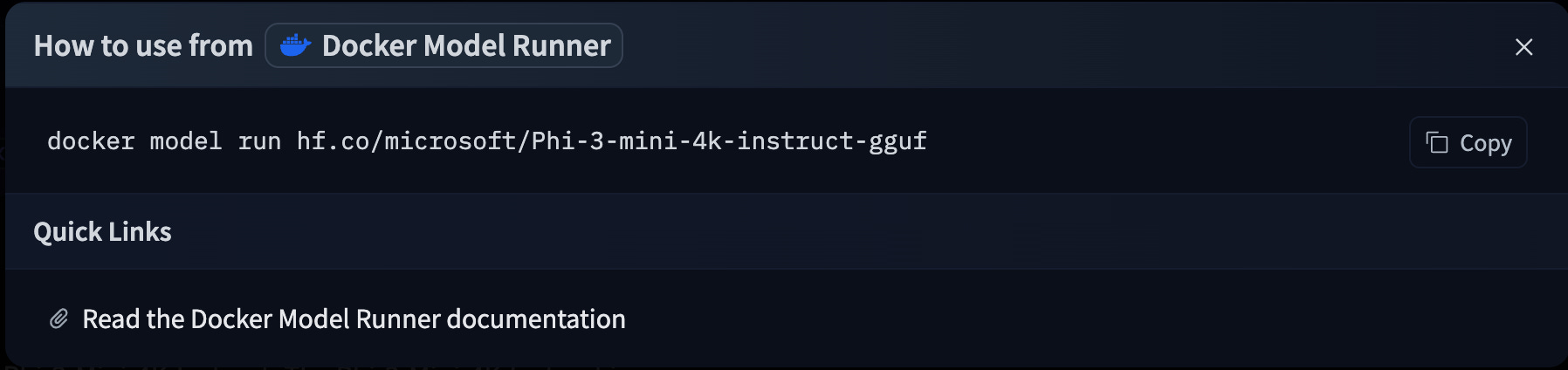
Note that it uses the run command and not the pull command. This operates like the
docker runcommand - it will look for the model locally, and if not available, will try to pull it from the registry.
We will use the pull command first and then run it:
docker model pull hf.co/microsoft/Phi-3-mini-4k-instruct-ggufIf it works, you should see the following output:
Downloaded: 0.00 MB
Model pulled successfullyWe will use the list command to show all the locally available models:
docker model listThis will return the following tables, and you can see that the Microsoft model is among the other models available on my machine:
MODEL NAME PARAMETERS QUANTIZATION ARCHITECTURE MODEL ID CREATED SIZE
ai/llama3.2:latest 3.21 B IQ2_XXS/Q4_K_M llama 436bb282b419 4 months ago 1.87 GiB
ai/gemma3n:latest 6.87 B IQ2_XXS/Q4_K_M gemma3n 800c2ac86449 5 weeks ago 3.94 GiB
hf.co/bartowski/llama-3.2-1b-instruct-gguf 1.24B llama 7ca6390d8288 10 months ago 808M
hf.co/microsoft/bitnet-b1.58-2b-4t-gguf 2.41B bitnet-b1.58 a4b724af32b7 3 months ago 1.19B
hf.co/microsoft/phi-3-mini-4k-instruct-gguf 3.82B phi3 3e95604429e2 15 months ago 7.64B Last but not least, we will launch the model using the docker model run command:
docker model run hf.co/microsoft/Phi-3-mini-4k-instruct-ggufWe can now interact with the model from the CLI, for example, let’s ask the following question:
What is the capital of the United States of America?
And here is the output:
Interactive chat mode started. Type '/bye' to exit.
> What is the captical of the United States of America?
The capital of the United States of America is Washington, D.C.Running Hugging Face Model with Python
Running with LLMs from Hugging Face with DMR and Python follows the exact same workflow as shown in the previous issue. In this case, this is how you can run the above workflow with Python:
import openai
# Setting the model URL for running within a container
base_url= "http://model-runner.docker.internal/engines/v1"
# Setting the client
client = openai.OpenAI(
base_url = base_url,
api_key = "docker"
)
# Calling the model
completion = client.chat.completions.create(
model="hf.co/microsoft/phi-3-mini-4k-instruct-gguf",
messages=[
{"role": "system", "content": "You are a helpful AI assistant."},
{"role": "user", "content": "What is the capital of the United States of America?"}
],
)
# Parsing the output
print(completion.choices[0].message.content)As expected, this will print the following text:
The capital of the United States of America is Washington, D.C.Summary
Docker Model Runner follows the Open Container Initiative (OCI) standards for model storage using the GGUF format. This gives users access to the largest AI model hub — Hugging Face. In this issue, we walked through how, in just a few simple steps, you can filter and identify an AI model on Hugging Face, then pull and run it locally with DMR.
Resources
Getting Started with Docker Model Runner - link
Running LLMs Locally with Docker Model Runner and Python - link
Hugging Face models - https://huggingface.co/models
Docker Desktop documentation - https://docs.docker.com/desktop/
Docker Model Runner Documentation - https://docs.docker.com/ai/model-runner/
Available LLMs on Docker Hub - https://hub.docker.com/u/ai